난 실물 책은 싸그리 전부 e-Book으로 만들어버리고 싶은 사람이다.
미래엔 실물 책이 반드시 없어졌으면 한다. 실물 책은 무겁고 부피가 커서 물리적으로 굉장히 비효율적이다.
e-Book으로 싸그리 만들어서 죄다 불과 약 1kg 남짓한 iPad에 넣으면 몇 천~몇 만권을 언제 어디서든 볼 수 있고 원하는 내용을 몇 초만에 뚝딱 검색할 수 있는데도 말이다.
그러나 여전히 국내 출판 업계에선, 저작권 문제도 있을 것이고.. 무엇보다 종이 값 포함하여 출판하면 동일한 내용으로 마진을 많이 남길 수 있는 이유 등으로 전자책 출판에 의도적으로 별다른 투자를 하지 않는 것으로 예상된다 (뇌피셜임).
나는 내가 구매하고 싶은 책이 전자책으로 이미 출판되어있을지라도 실물 책을 산 후 직접 e-Book으로 만들어서 사용하고 있는데 그 이유는, 전자책 전용으로 출판된 것들은 하나같이 가독성이 좋지 않기 때문이다 […]
아무튼, 그 동안 내가 가진 모든 책을 e-Book으로 제작해보면서 습득한 노하우와 그 제작 절차 등을 총 정리해보려고 한다.
비파괴식 vs 파괴식
북 스캔 방법은 크게 비파괴식과 파괴식으로 나눌 수 있다.
말 그대로, 스캐너로 책을 스캔하기 위해서 책을 파괴(재단)해야하느냐 안해도 되느냐의 차이이다.
비파괴식 스캐너
대표적으로 아래와 같이 Fujitsu ScanSnap SV600나 Tamtus Magic VT-500POT와 같은 제품이 있다.
비파괴식 스캐너라 하면 흔히 보이는 것이 Fujitsu ScanSnap SV600와 같은 오버헤드형 제품이다.
위 제품들과 같이 비파괴식 스캐너는 책을 한 장 한 장 직접 손으로 넘기면서 책을 스캔하는 방식으로써, 책에 손상을 가하지 않고 e-Book으로 제작할 수 있다는 것이 장점이다.
그 중에서도 오버헤드형 제품의 경우, 특성 상 후보정이 필수이기 때문에 책을 넘기면서 촬영할 시 책 고정을 위해 잡고 있는 손가락을 자동으로 제거해주는 등의 후보정 기능이 보통 내장되어있다.
하지만 아무래도 후보정이 완벽하지 않다보니 결과물의 품질면에서는 파괴식에 비해 좋지 않을 수 밖에 없고, 한 장 한 장 손으로 넘겨가며 스캔하는 것이 보통 번거로운게 아니다.
국산 제품인 Tamtus Magic VT-500POT의 경우는, V자 형태로 설계된 스캔면에 직접적으로 책이 맞닿아 스캔되는 방식이라 오버헤드형에 비교해서 결과물 품질이 더 좋을 것으로 예상된다.
하지만 구조 상, 페이지 한 장 한 장 넘겨서 스캔하는 행위가 오버헤드형에 비해 더 불편할 것으로 보인다.
더군다나, Tamtus Magic VT-500POT 제품은 정가가 약 430만원 가량이나 한다 […]
파괴식 스캐너
일반적으로 우리가 볼 수 있는 스캐너들이 이 분류에 해당한다.
파괴식 스캐너의 종류에는, 흔히 볼 수 있는 평면 스캐너도 있고 북 스캔에 적합한 양면 스캐너 등이 있다.
일단, 파괴식 스캐너는 책을 커터 칼이나 재단기 등으로 재단을 해야한다.
그래서 스캔 작업을 마친 후 남은, 재단된 책이 아까워 되팔기엔 보통 온전한 형태의 책을 원하지, 재단된 책을 구매하는 사람이 적어서 그냥 버릴 수 밖에 없다는 단점이 있다.
하지만 이러한 단점에도 불구하고, 스캔 속도 면이나 품질 면에서 파괴식 스캐너가 비파괴식 스캐너보다 월등하기 때문에 나는 개인적으로 파괴식 양면 스캐너를 적극 추천한다.
재단하고 남은 책이 아깝긴 하지만, 디지털화시킨 결과물이 있으니 그걸로 합리화하며 만족하면 되는 것이고 […]
어차피 디지털화한 이상, 실수로 파일을 삭제하지 않는한 반영구적으로 책을 보관할 수 있는 것인데 이왕이면 품질 좋게 저장해두는 것이 좋다고 생각하는 것이다.
준비물 및 비용
준비물
- [Hardware] Fujitsu ScanSnap iX500 (스캐너)
- [Hardware] 현대오피스 HC-600 (A4) (재단기)
- [Software] ABBYY FineReader 14 - 후보정용이므로 옵션임
- [Software] Adobe Acrobat Pro DC - 후보정용이므로 옵션임
현재 내가 e-Book 제작에 사용하고 있는 구성이다.
혹시나해서 말하자면, 재단기 사지 않고 커터 칼로 일일히 책 자를 생각하지말자 […]
나도 재단기가 무게랑 부피가 크니까 ‘그냥 커터칼로 자르면 되지 않을까..’ 라고 생각해서, 한 번 10장 정도 짤라보니 ‘아 이건 사람 할 짓이 아니구나’ 란 생각이 들어서 그냥 바로 재단기를 질렀던 기억이 있다.
뭐 ‘난 시간이 넘쳐흘러서 커터 칼로 자를래’ 라고 생각한다하더라도, 커터 칼로 자르면 사이즈가 일관성있게 재단되기가 힘들다는 점도 있어서 그냥 재단기 사는 걸 추천한다.
비용
- [Hardware] Fujitsu ScanSnap iX500 (스캐너) - 약 60만원
- [Hardware] 현대오피스 HC-600 (A4) (재단기) - 약 10만원
- [Software] ABBYY FineReader 14 - 옵션이므로 알아서..
- [Software] Adobe Acrobat Pro DC - 옵션이므로 알아서..
나 같은 경우는 후보정용 소프트웨어들을 제외하고 약 70만원 정도가 들었다.
e-Book을 제작하려고 장비를 세팅하기 전에는, 약 60권 정도를 북스캔 업체에 맡겼었는데 그 비용이 약 250만원 정도 나왔던 걸 감안하면.. 장기적으로 볼 때 결코 비싼 금액이 아니라고 생각한다.
물론, 북스캔 업체에 옵션이 여러가지 있었는데 OCR 작업이나 가독성 향상 처리, 그리고 수작업으로 해야하는 목차 하이퍼링크 작업 등 내가 항상 동일하게 꽤 많은 옵션을 붙였던 지라 가격이 좀 많이 나온 것일수도 있었을 것이다.
목차 하이퍼링크 작업은 수작업으로 해야 해서, 목차 1개당 400원이라는 사악한 가격을 내고도 항상 옵션을 붙여서 서비스 받곤 했었다 (이젠 그냥 내가 한다…).
제작 절차 및 절차별 노하우
자, 이제 본격적으로 제작 절차를 알아보도록 하자.
최소한 이 정도 후처리는 해줘야 e-Book을 읽을 때 편하게 다양한 상황에 대응할 수 있을 것이라 생각했기 때문에, 아래 열거된 작업들은 책 한 권당 내가 반드시 하는 작업들이다.
0. 절차를 진행하기 위한 기본 세팅
절차가 꽤 많기 때문에 단계별로 directory를 만들어서 관리하는 걸 추천한다.
나 같은 경우는 아래와 같이 관리하고 있다.
- 스캔 원본
- OCR 작업본
- 페이지 번호 및 책갈피 작업본
- 최종본 (3번 단계에서 목차 Hyperlink 작업을 한 것)
- 용량 축소본
1. 책 재단
일단 재단기로 책을 자르자.
단, 자를 때 적당히 깊이 잘라야한다. 깊이를 너무 얕게 자르면 페이지끼리 서로 붙기도 하거니와 접착제가 남아있기도 해서, 스캐너에 들어가면 스캔 센서부가 빨리 더럽혀질 가능성이 있다.
파도 타기
책을 재단하고 나서는, 페이지끼리 서로 붙어있는 경우도 있으니 두 손으로 책을 가로로 잡고 한 번 파도를 타준다.
한 번 꿀렁 꿀렁 해주면 붙어 있는 페이지들이 서로 떨어지게 된다.
2. 책 스캔
스캐너로 책을 스캔한다.
나 같은 경우는 어차피 후보정 작업을 하기 때문에, 스캐너 공식 소프트웨어에 있는 여러가지 각종 보정 기능들은 최대한 해제하고 스캔을 한다.
Fujitsu ScanSnap iX500 제품으로 스캔할 때의 내 구체적인 세팅을 알고 싶다면, 여기에서 볼 수 있다.
페이지 수 검증
스캔을 하고 난 다음엔, 가끔 페이지 일부가 누락되는 경우가 있기 때문에, 스캔된 페이지 수가 일치하는 지 반드시 최소한의 검증을 해줘야 한다.
스캔 원본인 PDF 파일의 페이지 수와 책의 페이지 수가 일치하는 지 확인하는 것이다.
혹시나해서 말하는 데, 실물 책 그거 한 장 한 장 손으로 넘겨가며 페이지 수 세는 사람은 없길 바란다 […]
책에는 기본적으로 페이지 수가 나와있기 때문에, 페이지 수가 나와있지 않은 일부분 (책 겉표지를 포함한 극초반부와 극후반부 부분)만 세어서 더하면 된다.
3. OCR 작업
ABBYY FineReader 14로 OCR 작업을 해준다.
스캔을 할 때 ScanSnap Home 공식 소프트웨어에도, 내장된 ABBYY FineReader for ScanSnap 제품이 있어 OCR 처리를 할 수 있긴 하지만, 한글 인식률이 ABBYY FineReader 14가 훨씬 좋아서 내장 OCR 인식 기능은 끄고 스캔을 한 후 ABBYY FineReader 14로 후처리해주고 있다.
ABBYY FineReader 14가 기능이 굉장히 강력해서, 한글 인식률도 매우 좋을 뿐만 아니라 온갖 구조화된 요소들(레이아웃, 표 등)도 전부 인식해준다. 그리고 페이지 기울기 보정 기능도 ScanSnap Home의 내장 기능보다 훨씬 정확하다.
ABBYY FineReader 14로 OCR 처리를 하여 검색 가능한 PDF 파일로 저장을 하면 된다.
그리고 ABBYY FineReader 14을 통해 OCR 처리를 하여 저장하면 용량도 대폭 축소된다.
ABBYY FineReader 14 세팅
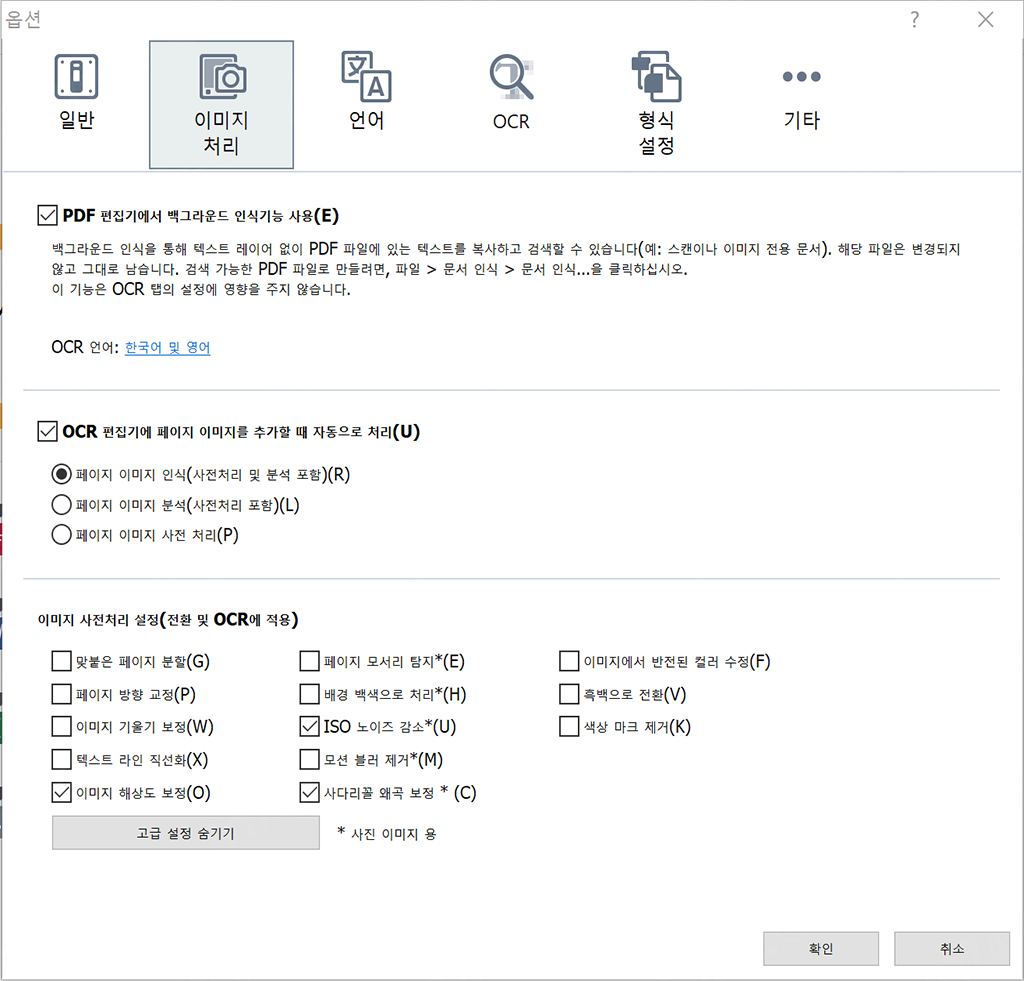
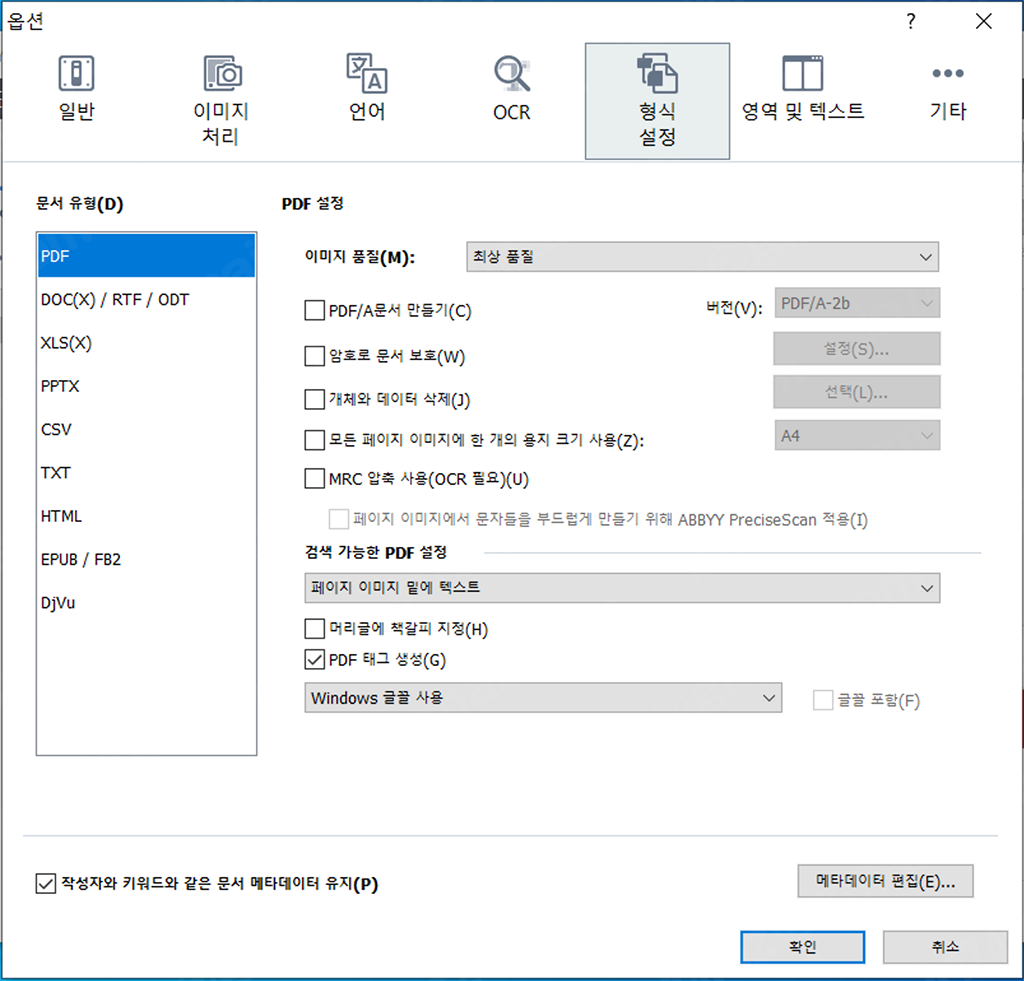
위는 내가 ABBYY FineReader 14로 OCR 작업을 할 때 사용하는 세팅이다.
- MRC (Mixed Raster Content) 압축은 이미지를 포함한 요소들을 Image Segmentation 기법을 사용하여 효율적으로 압축하는 기술인데 굳이 이미지를 압축하여 화질을 저하시키고 싶지 않아서 체크 해제 했다.
- ABBYY Precise Scan 기능은 Raster image를 Vectorization하여 글씨 가독성을 향상하는 기술인데 직접 써보니 확실히 용량도 꽤 줄어들고 글자 가독성이 향상되긴 한다.
하지만 Vectorization이 되었으므로, 글자를 확대해서 보면 당연히 매우 선명하긴 하나, Vectorization을 하는 과정에서 글자의 표면이 매끄럽게 처리가 되지 않아 울퉁불퉁하게 표현되고 오히려 너무 선명해서 눈이 쉽게 피로해지는 단점이 있었다.
그리고 가장 큰 문제는, ABBYY Precise Scan 기능이 적용된 PDF 파일을 읽으려 하면 로딩에 시간이 매우 많이 걸린다는 것이다. 아마도 그 수 많은 글자를 Vectorization했으니 그 Vector 정보들을 읽고 Rendering하는 과정에서 많은 연산이 수행되기 때문에 그렇게 시간이 소요되지 않나 싶다 (PDF 파일 하나 여는 데 몇 분씩 걸리기도 했다).
아무튼 개인적으로는 굳이 그렇게 글자 표면을 불균일하게 만들면서까지 용량 축소, 시인성 향상 효과를 보고 싶진 않았고, 특히나 파일 로딩 시간이 너무 길어져서 이 옵션을 체크 해제했다.
4. 페이지 번호 재정의 작업
실제 책들을 보면, 책 표지를 포함해서 책의 극초반부나 극후반부 일부 페이지들은 페이지 번호에 포함이 안되기 때문에 Adobe Acrobat Pro DC로 페이지 번호 재정의 작업을 해줘야 한다.
PDF 파일을 읽다가 PDF Viewer에서 특정 페이지로 가고 싶은 경우가 있는데 페이지 번호 재정의 작업을 하지 않은 채로 이동을 원하는 페이지 번호를 입력하면, 책 표지를 포함해서 페이지 번호에 포함되지 않는 페이지들도 함께 카운팅된 페이지 번호로 이동하기 때문에 몇 페이지가량 차이가 난 곳으로 페이지 이동을 하게 된다.
그래서 이런 경우를 방지하기 위해 페이지 번호 재정의 작업을 하여 페이지 번호를 일치시켜줘야 하는 것이다.
페이지 번호가 없는 페이지의 경우
실물 책에서 페이지 번호가 표시된 페이지의 경우에는 Adobe Acrobat Pro DC로 페이지 번호 재정의를 하여 페이지 번호를 일치시켜주고, 나머지 부분(책 표지를 포함한 책의 극초반부나 극후반부 일부 페이지들)은 Alphabet 대문자(A, B, C, …, Z) 표기로 설정해준다.
그리고 페이지 번호를 A에서 Z까지 다 소진하고도 여전히 페이지 번호가 없는 페이지가 남았다면, 다음과 같이 Double Alphabet 대문자 표기(A, B, C, …, Z, AA, BB, CC, …, ZZ)로 설정해준다.
그럼 ZZ까지 간 다음, 여전히 페이지 번호가 없는 페이지가 남았으면 어쩌냐고?
아직 그 정도로 머리와 꼬리가 긴 책은 만나보지 못했다 […] (나중에 생각하도록 하자)
한 책이 분권되어있는 경우
한 책이 분권되어있는 경우가 있다.
주로 자격증이나 시험 준비 책들이 그러한데, 앞에는 문제지고 뒤에는 정답지 이런 식이다.
그런 경우, 나는 페이지 번호를 1-[페이지 번호], 2-[페이지 번호], … 이런 식으로 재정의한다.
즉, 문제지는 표지부터 시작해서 1-A, 1-B, …, 1-Z, 1-AA, 1-BB, …, 1-ZZ, 1-1, 1-2, …, 1-300 이런 식으로 페이지 번호를 매기고, 정답지는 2-A, 2-B, …, 2-Z, 2-AA, 2-BB, …, 2-ZZ, 2-1, 2-2, …, 2-300 이런 식으로 페이지 번호를 매긴다.
5. 책갈피 작업
PDF Viewer로 책을 보다가 언제든지 원하는 Chapter로 이동하기 위해 Adobe Acrobat Pro DC로 책갈피(Bookmark) 작업을 한다.
앞서 페이지 번호 재정의 작업을 먼저 했기 때문에, 책갈피 작업이 더 수월하다.
책갈피는 목차 페이지는 무조건 등록하고, 나머지는 큰 Chapter (Depth 1짜리1)들만 등록한다.
세부 Chapter들의 책갈피 작업은 굳이 할 필요 없다. 어차피 다음 단계인 6. 목차 Hyperlink 연결 작업이 완료되면, 필요할 경우 책갈피를 통해 목차로 이동한 다음 해당 세부 Chapter 글자를 눌러 해당 페이지로 이동할 수 있게 되기 때문이다.
6. 목차 Hyperlink 연결 작업
이 단계는 목차 페이지에서 각 Chapter 글자를 눌렀을 때 해당하는 페이지로 이동되게끔 하기 위한 작업이다.
즉, 책을 보다가 예전에 봤던 페이지가 궁금해서 다시 보고자 할 때 Bookmark 중 목차를 눌러 목차 페이지로 이동하고, 여기서 원하는 Chapter 글자를 눌러 해당 페이지로 이동하는 UX (User eXperience)를 구현하기 위한 것이다.
목차 Hyperlink 작업은, Adobe Acrobat Pro DC로 직접 해당 글자에 Bounding Box를 마우스로 그려서 Hyperlink 처리해줘야하는 것이기 때문에 목차 항목이 많을수록 상당한 노가다가 필요하다.
단, 간혹 목차 항목 중에 페이지 번호가 표시되지 않은 항목이 있는 데 이런 항목은 당연하게도 Hyperlink 연결 작업을 해줄 필요 없다.
앞에서 해온 절차들은 Utility들을 통해 자동화가 가능한 작업이지만, 이건 순전히 노가다라 많은 인내력이 필요하다. 화이팅.
7. 파일 사이즈 축소 작업
위 6번 단계까지 끝났으면 그 것은 최종본이 되는 것이다.
최종본은 별도로 백업해두고, 이제 실제로 iPad 등 기기에 넣어서 읽을 용량 축소본이 필요하다.
최종본은 3. OCR 작업 단계에서 아무리 용량이 대폭 축소되었다고 한들, 여전히 용량이 커서 그대로 Portable 기기에 넣어 읽기에는 무리가 있다. 아마 파일을 읽는데만 해도 꽤 시간이 오래 걸릴 것이다.
일반적인 분량의 책(200 pages 이상)들의 경우, 경험상 최종본 파일 사이즈가 200~300MB 정도 되고, 페이지 수와 그림이 많은 책의 경우는 약 2GB 정도까지도 된다.
Adobe Acrobat Pro DC에서 [File] - [Reduce File Size]를 누르면 웬만한 PDF 용량을 100MB 이하로 축소할 수 있다.
주의할 점
이 단계를 수행하기 전에 주의할 점이 있다.
이 작업은 Image Processing이기 때문에 GPU 연산이 많이 필요하다. 따라서 GPU가 굉장히 좋은게 아니라면 한 번에 한 파일만 용량 축소 작업을 진행하길 권장한다. 동시에 여러 권 진행했다가 PC가 Freezing 걸리면 다시 처음부터 작업해야하는 경우가 있다. 게다가 시간도 매우 오래 걸린다.
그리고 PC의 HDD나 SSD에 최소 200GB 이상은 여유 공간을 확보해놓길 권장한다.
PDF 파일의 이미지를 한 장 한 장 압축 풀어서 Image Processing을 하는 것으로 추정되는데, 용량이 어마무시하게 소모된다.
예전에 페이지 수와 그림이 많은 PDF의 파일 사이즈 축소 작업을 진행했다가, 그 한 파일에 200GB 가량이 소모되는걸 본 적 있다. 물론 작업이 끝나면 Cache 파일들은 다 지워지기에 다시 용량이 확보된다.
Footnote
-
만약 Chapter의 구조가 1. e-Book 제작 방법 > 1.1. 책 재단하기 > 1.1.1. 재단기에 책 넣기 이런 식으로 구성되어있다면, Depth 1이란 말은 1. e-Book 제작 방법 까지를 말하는 것이고, Depth 2란 말은 1. e-Book 제작 방법 을 포함하여 1.1. 책 재단하기 까지를 말하는 것이다. ↩